Leafly is an information aggregator for cannabis. They maintain a profile for most of the dispensaries in the state. In a project to study and make predictions about what drives the Washington state cannabis industry, I've scraped the following features from the Leafly website for each dispensary for which it was available:
- Average customer rating and number of customer reviews
- Inventory counts (number of products under descriptions like "flower", "edibles", "concentrates", etc.
- Categorical qualities, such as whether or not the store is ADA accessible or has an ATM onsite
- Metadata such as name, address, phone number, etc.
The combination of these features gives us a profile of each dispensary that allow us to draw insights into what makes for a successful dispensary.
Obtaining the Data
Scraping Leafly
Getting data I was looking for off of from Leafly's website was by far the most difficult and complex task in the course of this prediction project. To tackle this, I split up the task into two primary functions:
- Getting a list of all of the dispensaries with a profile on Leafly, along with some basic metadata about each (most importantly, the URL suffix that points to the dispensary's profile page)
- Going to each individual dispensary profile and extracting specific data of interest available there.
Getting a list of all of the dispensaries
In a dream world there would be a single page somewhere on Leafly pointing to each of the 500 or so dispensaries in Washington, making it trivial to extract all those links and continue on to get all my data and accomplish great things. This is not that world. Instead, Leafly has this lovely interface of a map view and tiles, dynamically rendered and updated as you move the map or search a new area. Unfortunately, a given map view doesn't actually render all of the dispensaries in that view, nor does the URL interface allow for the map to be easily searched in a programmatic way. Modern javascript allows for some beautiful web design, but it wasn't giving me any handouts here.
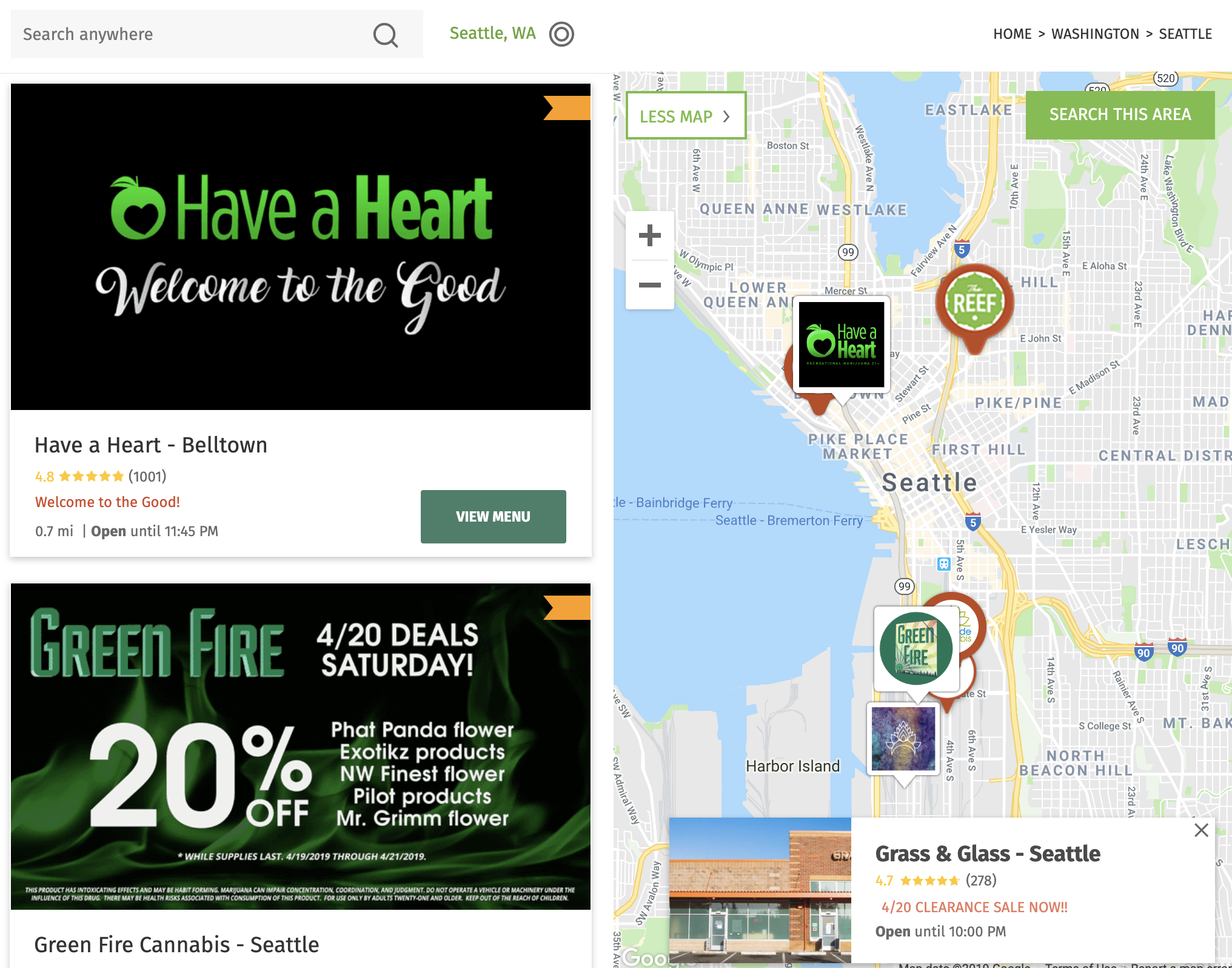
That's where a little bit of network traffic sleuthing comes in. It turns out that if you dig into the calls and requests made by the site while the page is loading you can find a searchThisArea API call being made to render the webpage, the results of which include data on every dispensary within a rectangle described by latitude and longitude coordinates. While Leafly doesn't technically offer a public facing API, I was able to exploit this request URL to get what I needed. I wrote a grid search function to systematically enter lat/lon coordinates that would traverse the entire state of Washington one little box at a time.
From here the solution was mostly just a straightforward process of converting request responses to JSON and storing my desired data to a dictionary, I do want to talk briefly about what I thought was a clever response to the API return limit of 200 results per search. Backing up a little bit, in order to avoid being detected as an automated scraping algorithm and having my IP blacklisted from Leafly, my algorithm would wait a random amount of time (anywhere from 0.5-2.5 seconds) between each request in order to obfuscate the fact that it's a data-sucking robot. The downside of this for me is that the smaller my search area in my grid search, the longer it would take me to scrape the whole state.
My solution to that was to implement what approximately amounts to a recursive tree search of the state that tends to roughly minimize the number of API calls required to collect all of the data. I initialized the search by instructing my algorithm to search the entire state of Washington. This invariably returns data on exactly 200 dispensaries, as that's where the API limits the call—problematic when what's desired is all of the dispensary. So I set up my routine such that the first thing it does is check whether or not the number of responses equals 200. If so, it simply subdivides the search area into four smaller search areas and searches them by the same routine. This has the effect of automatically determining an appropriately zoomed in search area when moving over dense areas like Seattle while searching from zoomed way out while moving over the more rural parts of the state.
Getting dispensary specific data
So that was fun, and by the end of the routine I had a data dictionary with entries for a little over 600 dispensaries (my coordinates overlaps into Oregon a bit, and from the looks of it the overachieving stoners down in Portland out-consume Seattle by about 2:1).
From here, I had a new scraping algorithm to write. To get the data off of each individual dispensary page, I used Selenium to fire up an instance of Chrome to be programmatically driven to each page and select and scrape the needed information. Of course, the first step in the process was to have my robobrowser tell Leafly that it was indeed over 21 years of age.
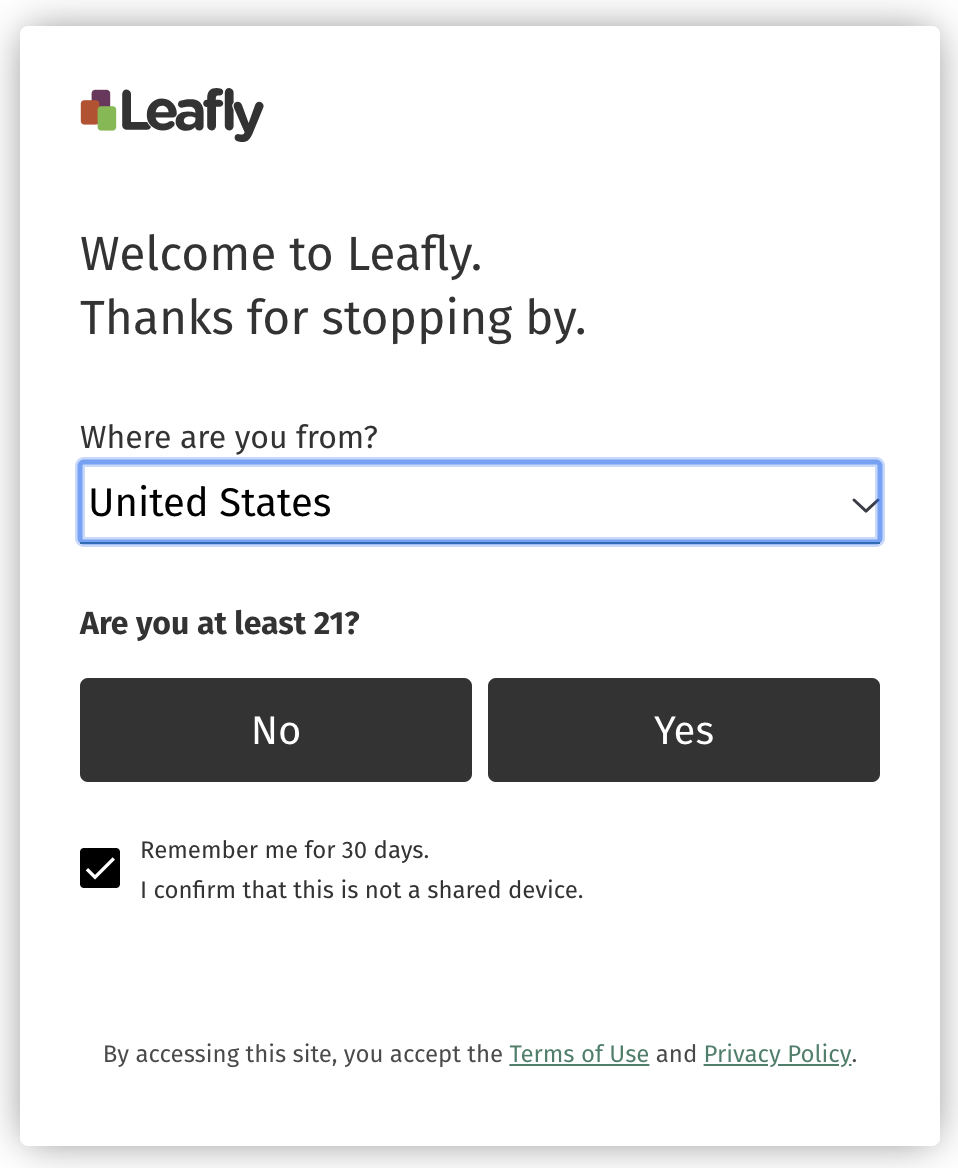
Simple enough, just had to tell the robot to find the Yes button and click it, and…success! My robot successfully thwarted their robot's defense perimeter and we're off to the races. On each page, I pulled every bit of data I could find that might be relevant, from continuous variables like ratings, number of reviews, and quantity of each product found to be in stock to the categorical things like whether or not they had an ATM on site or are ADA accessible.
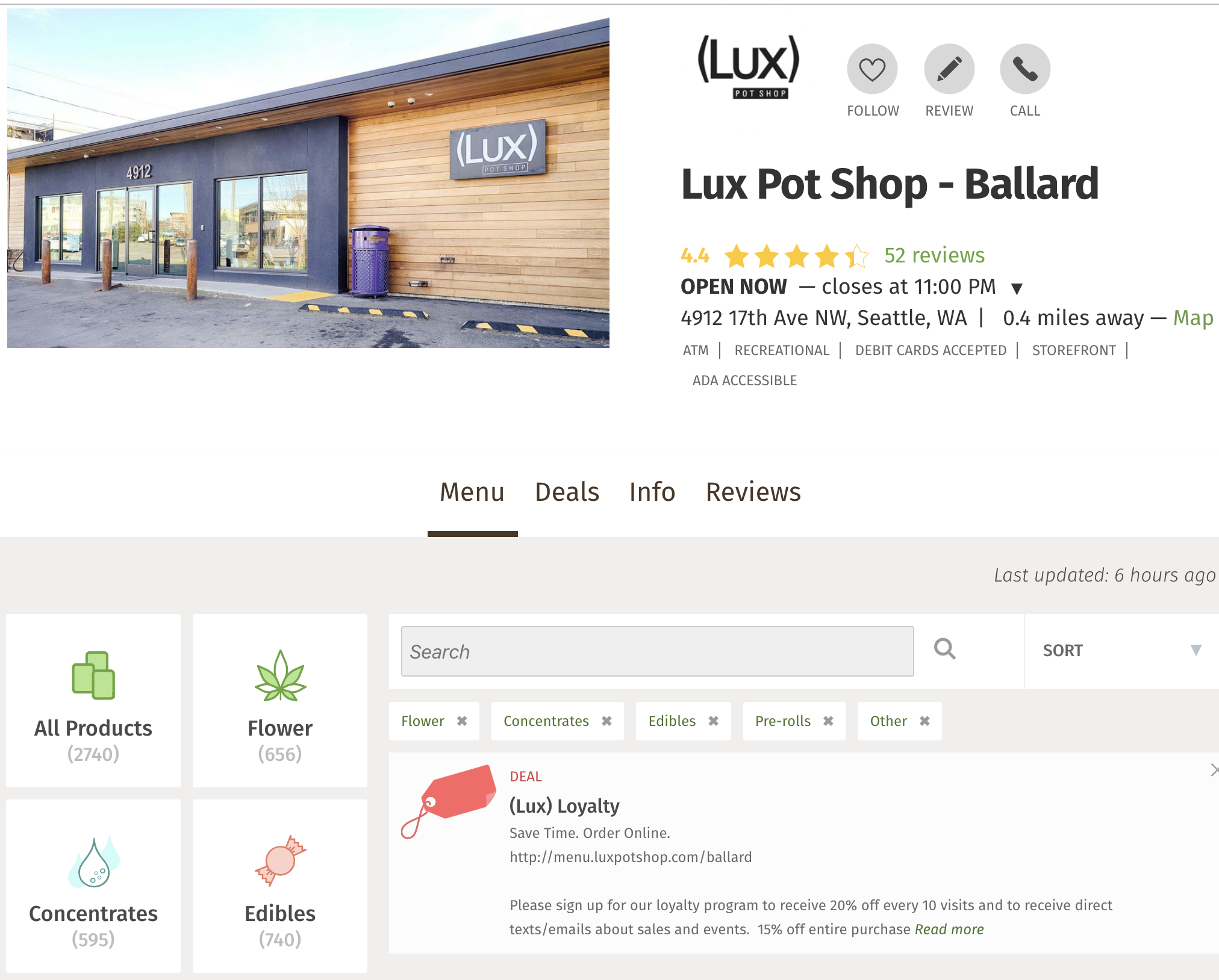
And that was that! With a couple dozen fields of data on each dispensary now stashed away in a JSON file, I could move on to scraping some simpler sources of data.
Using the data
If you enjoyed this, check out my article on how I used this data to make predictions about what gets the Washington cannabis industry high.
Comments
comments powered by Disqus